I enjoy making data visualizations. Here are some examples of my work. All were done in R.

Neuroscience, addiction, development, genetics, and statistics
I enjoy making data visualizations. Here are some examples of my work. All were done in R.

In an interaction analysis, the probability of a false-positive result increases as the correlation between our covariate and predictor increases, and as the effect of our covariate x predictor interaction increases. The extremely simple solution is to include all covariate-by-predictor interactions in your model!

Clustered data - such as multiple observations per individual, animal, or cell - are quite common in neuroscience research. Here I walk through an introduction to one approach to adjusting your analyses for clustering - block permutations and bootstrapping - that is widely applicable and makes very few assumptions.
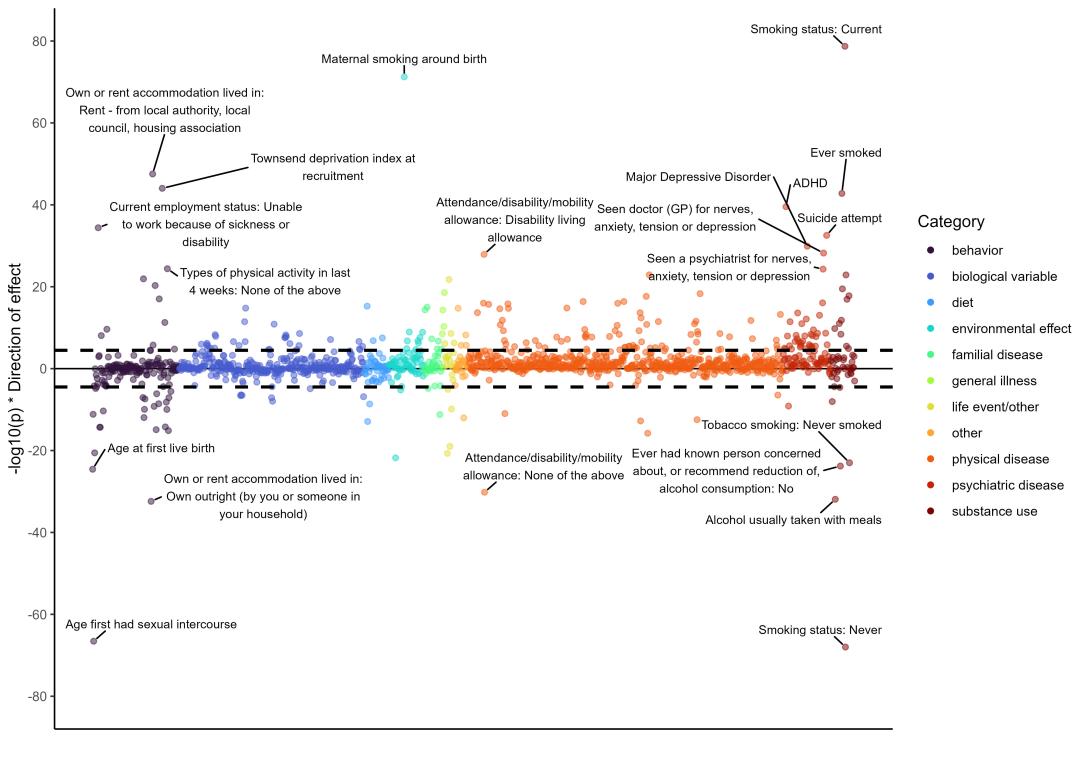
Here is my analysis of 'what correlates with how well someone climbs?'.

This is a short post on how to quickly get started using Turbo with your ggplots.
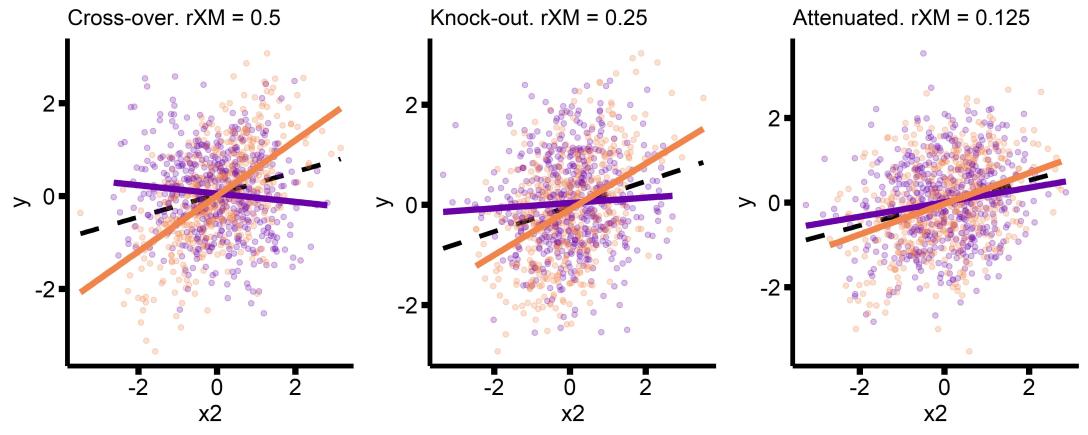
If my sample is just barely large enough to detect my main effect, the smallest interaction that I can reasonably expect is a knockout effect.
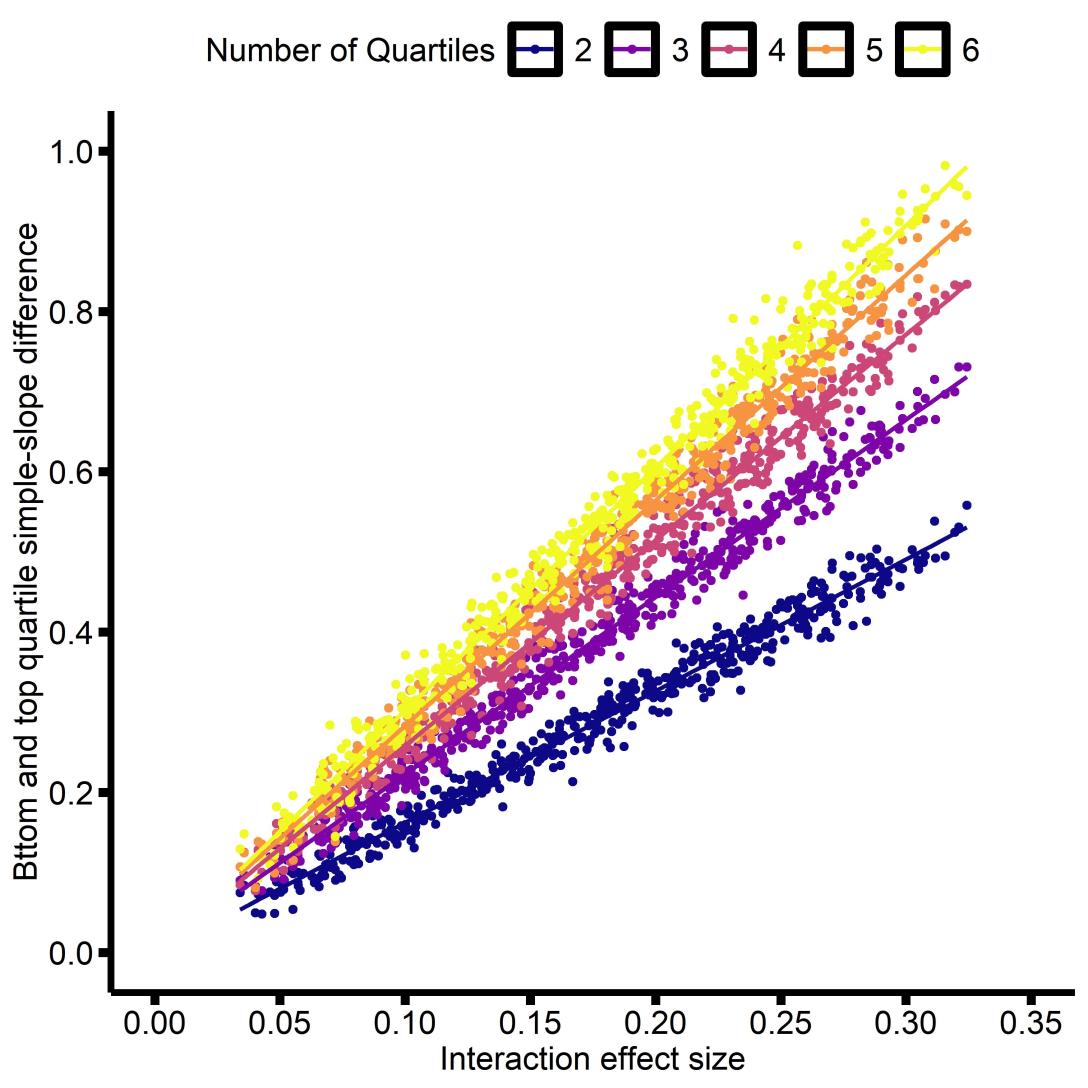
For an interaction effect size bXM, the difference between the simple-slopes of the top and bottom quartiles Q will be approximately: bXM * (ln(Q) +1)
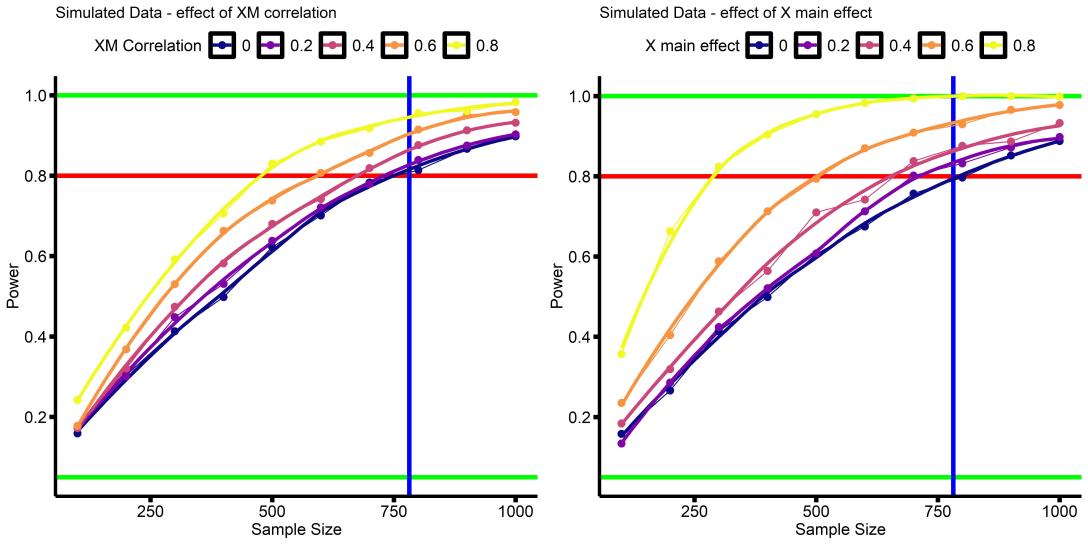
In this series I try to convey a couple of insights about power for interactions in linear regressions. First, how to do a power analysis for a interaction in a linear regression (this post), then interpreting the effect size of a interaction (part 2), and finally thinking about how large (or small) an effect size it is reasonable to plan for (part 3).
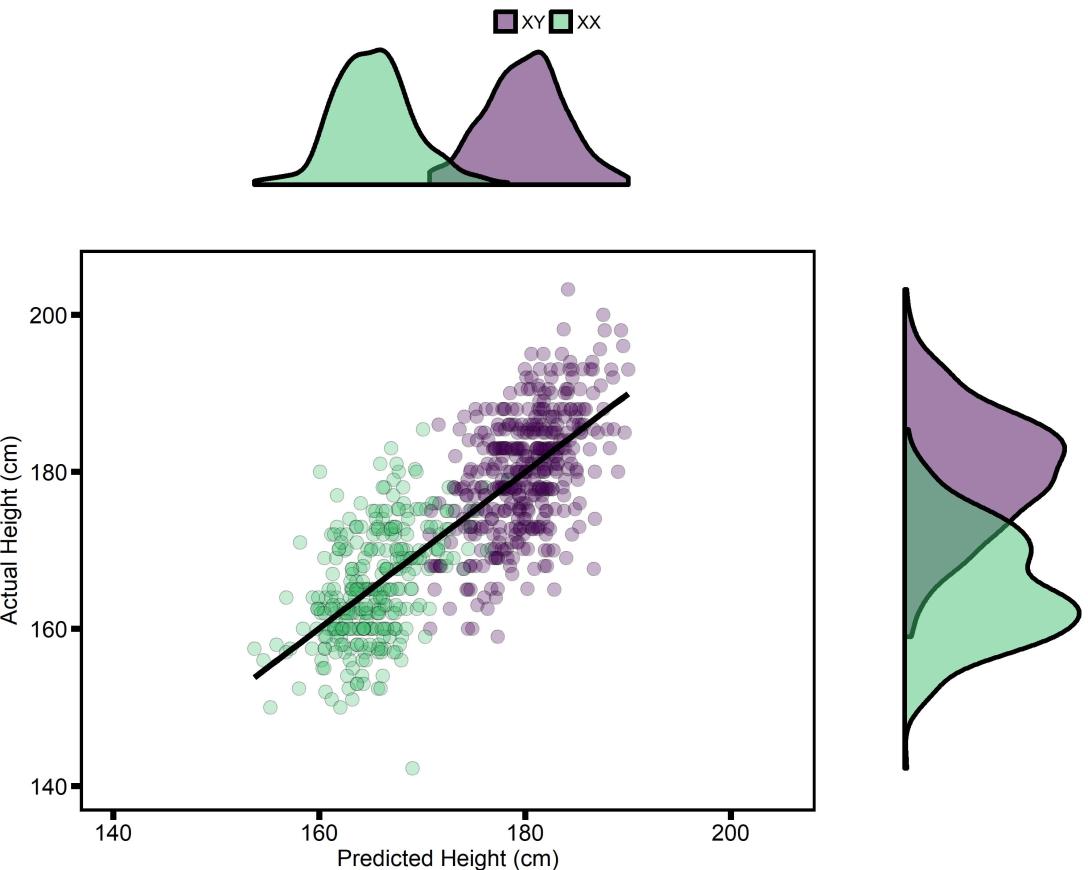
In my first post I showed how to build a simple model, using only genetic information, that predicts height, with 53% accuracy in an independent sample. In this post I’m going to improve that model, which will ultimately result in a model with 64% accuracy in an independent sample - an 11% improvement!

In this post I use R to show how to make what I’ve been using as an alternative to the standard bar graph - a scatter box violin plot.
crowdAI is a VERY cool site that hosts machine learning competitions. They recently hosted a competition using data from openSNP, a website that lets anyone upload their genetic data, making it publicly available. About 3,500 people have uploaded some amount of their genetic data (many people just upload the mitochondrial portion), and 921 also reported their height. The crowdAI competition was, very simply, can you predict Height in a subset of these people, using the genetic data from everyone else to train a model?
And? I won!!! My best model predicts 53.45% of variance in Height, while the current next-best predicts 48.62%. But there’s a catch, even though it was a “machine learning”" competition, I didn’t actually use any ML…oops
This post is intended to give an explanation of why I participated and how I won, with the hope that others with more expertise in ML can benefit from my knowledge in genetics....
