
Edit 8/9/22: This ideas discussed in this blog series are now published as a tutorial paper.
Edit 5/24/21: I’ve turned the code underlying these posts into an R package: https://dbaranger.github.io/InteractionPoweR. I’d recommend using this package for your own power analyses, rather than the original posted code, as it’s a lot easier to use, has more features, and I’ve fixed some minor errors.
In Part 1 I covered some aspects of what affects power for an interaction analysis, and in Part 2 I talked about interpreting interaction effect-sizes in terms of their ‘simple slopes’. In the next post, Part 4, I’ll cover which covariates are needed when testing an interaction.
Let’s start with a hypothetical – there is a main effect which I believe, and it has a effect of r=0.25. I want to collect my own sample to replicate this effect, and I want to test whether this is moderated by a second variable (an interaction). How large a sample should I collect? As always, see the R code for how to generate these plots.
pwr.r.test(r=0.25,sig.level = 0.05,power = 0.8)
approximate correlation power calculation (arctangh transformation)
n = 122.4466
r = 0.25
sig.level = 0.05
power = 0.8
alternative = two.sidedWe see from the above power calculation that to replicate my main effect, I would need at least N=123. If I collect a sample of that size, what kind of interaction effect will I be able to detect? In Part 2 I showed that the difference in simple slopes is proportional to the interaction effect size. If we know that the main effect is r=0.25, and we detect the smallest effect size we can with our sample, which is r=0.25 (see Part 1 for how to do this power analysis), then the difference in simple slopes between the bottom and top 50% of the data will be:
(log(2)+1)*.25
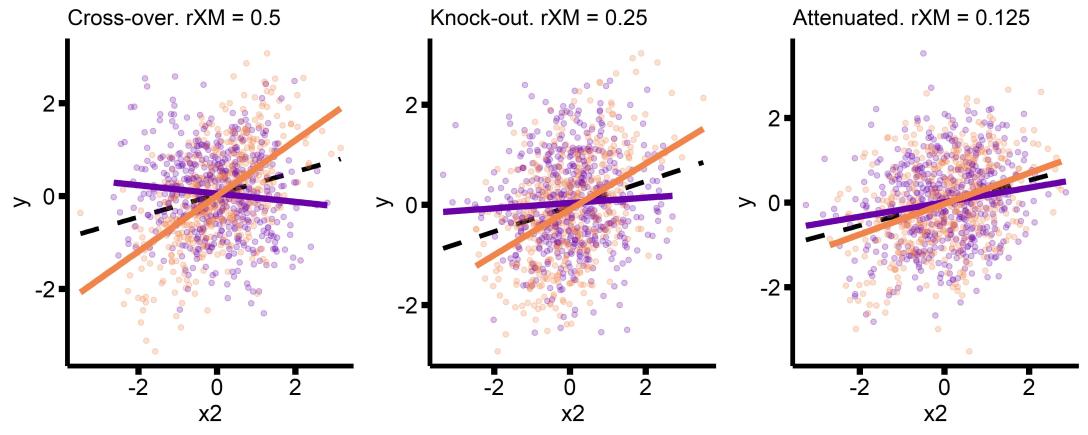
[1] 0.4232868So the slope in the top 50% of the sample will be ~ r=0.46 (.25 + 0.42/2), and the slope in the bottom 50% will be ~r=0.04 (.25 – 0.42/2) . So if my sample is just barely large enough to detect my main effect, the smallest interaction that I can reasonably expect is a knockout effect.

It’s up to the researcher whether or not this is a reasonable effect to expect, but I think the general point of the commentaries I referenced at the beginning of Part 1 [1,2,3] is that it makes sense to plan for smaller effects, attenuations of the main effect (panel 3 above), instead of knock-outs or crossovers. Why? Well first there’s the argument that interactions have a poor record of replicating, so caution and having extra power seems warranted. Second, consider that if an effect is important enough to be worth studying, perhaps it would be surprising if it were easy to identify subsets of the population where it isn’t present at all, or reversed. It seems more likely that the strength of the effect would be slightly modulated across different subsets of the population.
What interaction effect size should a researcher plan for then? The general suggestion seems to be at least 1/2 the size of the main effect. So if your main effect is r=0.25, plan for interactions of r=0.125.
pwr.r.test(r=0.125,sig.level = 0.05,power = 0.8)
approximate correlation power calculation (arctangh transformation)
n = 499.1926
r = 0.125
sig.level = 0.05
power = 0.8
alternative = two.sidedTo detect this effect, we would need at least N=500, or ~ 4-times the sample size needed to detect an effect of r=0.25. This is because the relationship between power and sample size is exponential. Hence, calls for samples that are 4x the size are based on detecting interaction effects that are 1/2 the size of the main effect, and samples that are 16x the size are for detecting interaction effects that are 1/4 the size of the main effect.
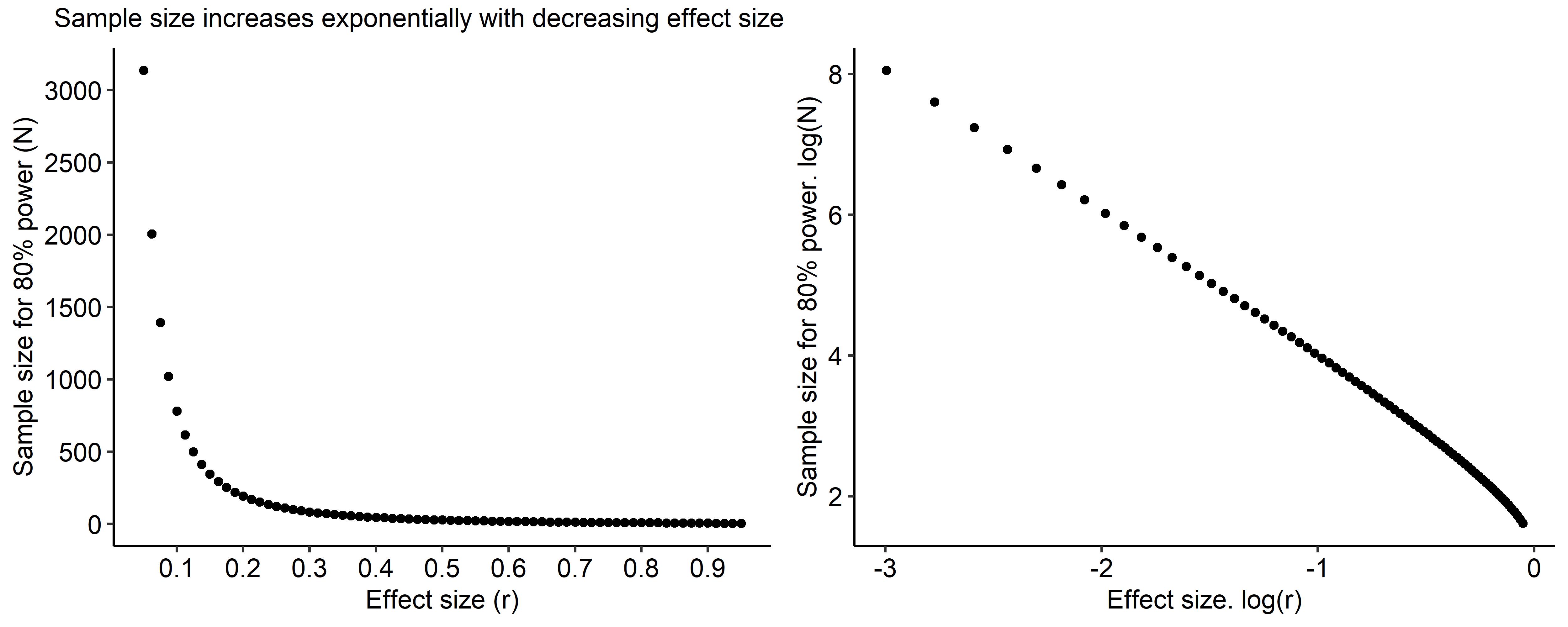
What about all those published interactions with small samples?
This isn’t to say that published interactions with small samples are false positives. But it is important to keep in mind that small samples will tend to over estimate an effect, proportional to how under-powered the sample is to detect the true effect. This is also why it isn’t a good idea to plan the sample size for a study based on the effect size in a pilot-study, because the pilot-study is nearly guaranteed to overestimate the effect of interest.
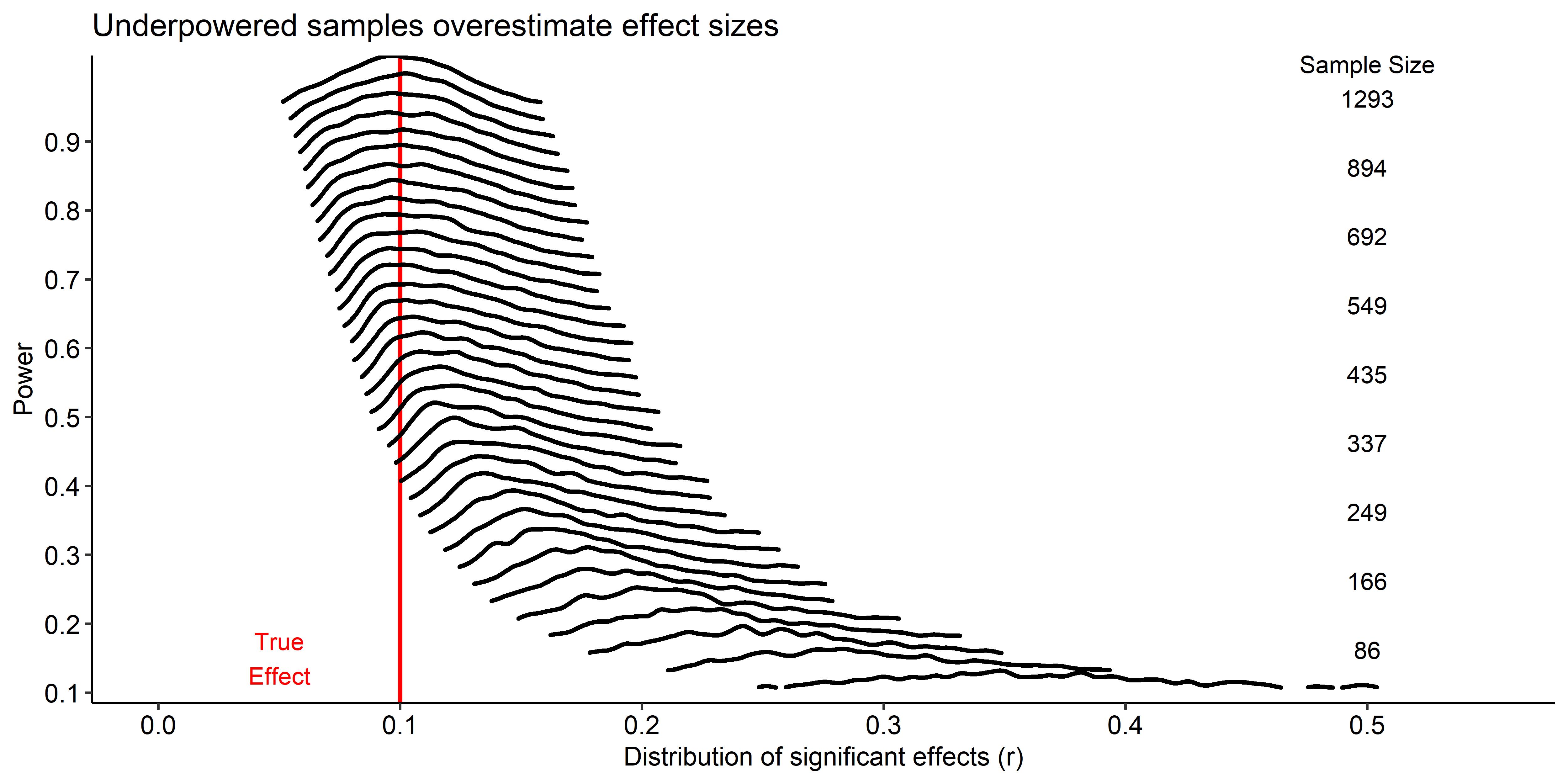
Note that this is also why publication bias is such a problem for meta-analyses. If most published results are significant (because the non-significant ones go unpublished), then it is likely that the published studies have overestimated the effect, and there is a big risk of the meta-analysis will overestimate the true effect size as well.
So how large a sample do I need?
To return to our original hypothetical, if there is a main effect of r=0.25, and I want to test an interaction, the sample should be large enough to detect plausible and meaningful effects. It’s up to you to decide what that means, but keep in mind that if the sample is only barely large enough to detect the main effect, then the only interactions that can reliably observed are quite large, and may not be plausible, depending on what the research question is.

[…] interaction effect-sizes (Part 2), and what sample size is needed for an interaction (Part 3). Here I’m going to talk about an issue that is near and dear to my heart – control […]
LikeLike
[…] Part 3: Determining what sample size is needed for an interaction. […]
LikeLike