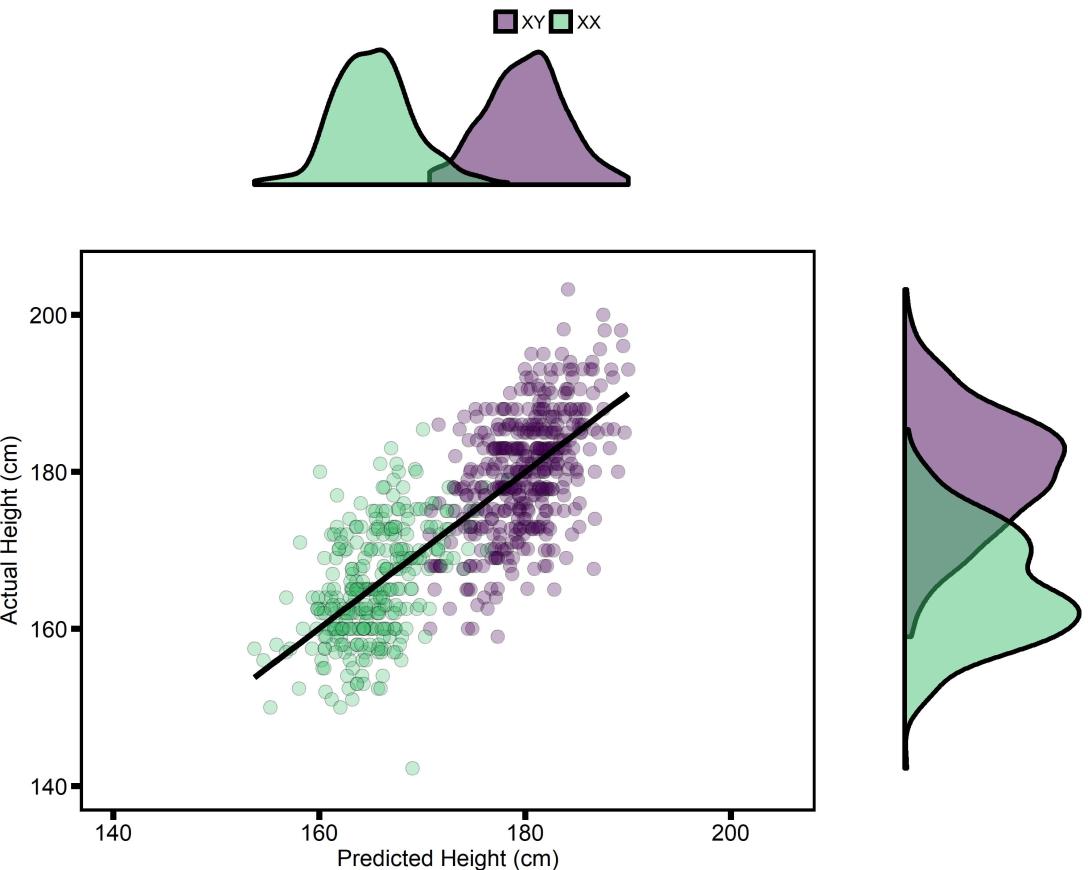
crowdAI is a VERY cool site that hosts machine learning competitions. They recently hosted a competition using data from openSNP, a website that lets anyone upload their genetic data, making it publicly available. About 3,500 people have uploaded some amount of their genetic data (many people just upload the mitochondrial portion), and 921 also reported their height. The crowdAI competition was, very simply, can you predict Height in a subset of these people, using the genetic data from everyone else to train a model?
And? I won!!! My best model predicts 53.45% of variance in Height, while the current next-best predicts 48.62%. But there’s a catch, even though it was a “machine learning”" competition, I didn’t actually use any ML…oops
This post is intended to give an explanation of why I participated and how I won, with the hope that others with more expertise in ML can benefit from my knowledge in genetics....